Published Development
My Supabase Overview

For the last few months, I’ve been extensively using Supabase - both for work and for my bachelor’s degree project. I feel like I’ve gained some experience with this BaaS, so this is my overview of working with it, including some quirks I faced, my preferred style of work, and some useful resources. I can’t cover everything, but I will talk about what I find most important.
Getting Started
If it’s your first time with Supabase, I recommend going through the official docs for about 5 minutes or using AI for the basic setup. In a nutshell, you get a PostgreSQL database, Auth, Storage (which can be integrated with S3), Edge Functions, Realtime, and much more included in your project. They also have a pretty generous free tier that I find is enough for my side projects.
Initial Setup
- Create a project in the dashboard.
- Install the Supabase CLI.
- Use
supabase loginto connect your account. - If you haven’t already, initialize the project in your repository with
supabase init. - Link your local project to a remote one with
supabase link. - To generate types from your database schema, use
supabase gen types typescript --project-id your-project-id > lib/database.types.ts. Add the--localflag to generate types from your local instance.
Helpful Resources
Right from the start, I want to share a few cool resources to use when you work with Supabase:
- For local development: Overview
- For quickly setting up UI: Supabase UI Library
- For generating SQL with AI: AI Prompts
Development Workflows
There are two main ways I’ve found you can work with Supabase: directly through the dashboard or locally on your machine. I want to discuss both.
Through the Dashboard
This approach involves using the SQL Editor in the Supabase dashboard, writing snippets, and executing them directly. It’s a comfortable experience if you are working on your own, on a project that nobody else is touching. I did it this way on my first Supabase project.
The main upside is that it’s really fast when you need to make quick changes, add or remove records, columns, etc.
However, because you do everything manually, you have no way of tracking these changes. This is why you would have trouble syncing with other developers working on the same project — a problem I think we can all understand.
Through Local Development
A better way (in my humble opinion) is to work via Local Development. It provides a way to actually sync between developers, avoid making changes to the same database when working on different features, and generate migration files.
Basically, the idea is that you have your own instance of Supabase running locally via Docker, and you can do whatever you want with it — modify data, schema, etc. You run it using supabase start.
The official docs do a great job of explaining the basic steps, so here are the commands I use most often:
supabase db diff -f filename- Generate a new migration file by comparing your local database with its state from the last migration.supabase migration up- Apply a migration to your local database.supabase db push- Push the latest migrations to your remote database. Usingsupabase db push --dry-runis useful for production to see the changes before applying them.- To roll back a migration, I usually check out the commit I want to revert to, then run
supabase db reset. After that,supabase db diff -f revert-latest.sqlwill generate a diff that drops the changes, which you can execute. Lastly, to fix the migration history, runsupabase migration repair --status reverted migration_id.
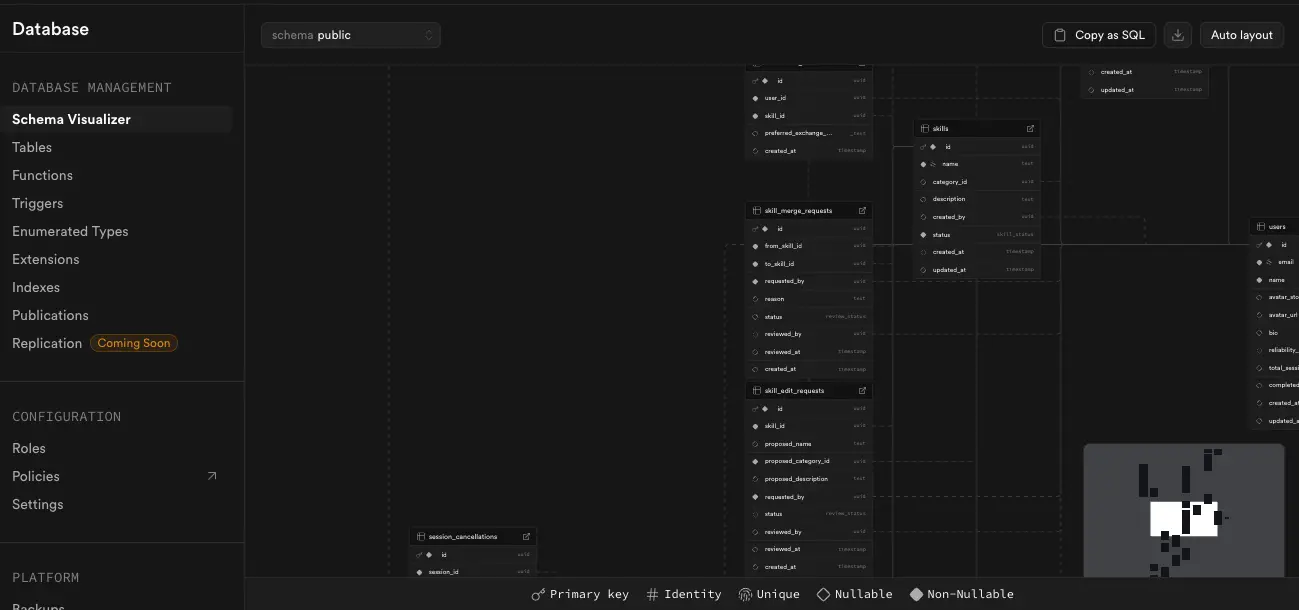
I also like the way you can see your DB, existing triggers, functions, indexes, and migration history.
Tips and Tricks
Here are some tips based on my experience.
- Check Your RLS Policies: Double, and triple-check your Row-Level Security policies when updating your database schema. We’ve all heard stories of misconfigured policies leading to data leaks. AI is usually good at generating them, but please, double-check its work.
-- examples of my some policies
create policy "Anyone can view active skill categories"
on public.skill_categories
for select
to authenticated, anon
using (is_active = true);
create policy "Only admins and moderators can manage skill categories"
on public.skill_categories
for all
to authenticated
using (
exists (
select 1 from public.admin_roles
where user_id = (select auth.uid()) and role in ('moderator', 'admin', 'superadmin')
)
)
with check (
exists (
select 1 from public.admin_roles
where user_id = (select auth.uid()) and role in ('moderator', 'admin', 'superadmin')
)
);- Secure Your Storage: Use policies for Storage as well, and also set limits on file size and extensions. For private files, use Signed URLs.
- Auto-Renew Signed URLs: You can implement automatic renewal when a Signed URL expires. I did this by simply storing
url_expires_atandurl_storage_pathin my database. - Utilize Extensions: Make sure to explore and utilize the available Postgres Extensions like
pg_cronfor scheduling jobs. - Edge Functions with Cron Jobs: I had a particular issue getting an edge function to work with a cron job. This comment really helped me set it up correctly.
- Use Postgres Functions for Complex Logic: I don’t like the supabase client library for building queries, at all. Almost all interactions are made via PostgreSQL functions, and then I call them with
supabase.rpc(). It gives more centralized logic, simpler client-side code, which fits my view.
-- example of such a function
create or replace function public.create_skill_listing(
p_user_id uuid,
p_skill_listing jsonb
)
returns jsonb
language plpgsql
security invoker
as $$
declare
new_listing public.skill_listings;
exchange_types_array text[];
learning_styles_array text[];
begin
-- Convert and validate incoming data from JSON
exchange_types_array := array(select jsonb_array_elements_text(p_skill_listing->'exchange_types'));
if not public.validate_exchange_types(exchange_types_array) then
raise exception 'Invalid exchange types provided.';
end if;
learning_styles_array := array(select jsonb_array_elements_text(p_skill_listing->'learning_styles'));
if not public.validate_skill_learning_styles(learning_styles_array) then
raise exception 'Invalid learning styles provided.';
end if;
-- Perform the insert with the validated data
insert into public.skill_listings (
user_id,
skill_id,
proficiency_level,
description,
exchange_types,
learning_styles
)
values (
p_user_id,
(p_skill_listing->>'skill_id')::uuid,
(p_skill_listing->>'proficiency_level')::public.skill_proficiency_level,
p_skill_listing->>'description',
exchange_types_array,
learning_styles_array
)
returning * into new_listing;
return to_jsonb(new_listing);
exception
when unique_violation then
raise exception 'You already have a listing for this skill.';
end;
$$;- Batch Uploads: If you need to batch upload media to storage, using AI to generate a Python script is very efficient.
- Database Migration: For migrating from one Supabase project to another, check out this guide.
- Next.js Caching: Be aware that when you use
createServerClient()in Next.js middleware or route handlers, it can unexpectedly cache responses. I spent about three hours figuring this out! To avoid it, pass a custom fetch option to disable caching:
// Pass this option in createServerClient()
options: {
global: {
fetch: (url: any, options = {}) => {
return fetch(url, { ...options, cache: "no-store" });
},
},
},Conclusion
Overall, Supabase fits really well for many use cases. I can’t speak to how it scales for large production applications, but for low-to-mid-sized projects, the ecosystem it provides feels extensive and robust. However, you have to understand the consequences of vendor lock-in. As always, “it depends.” :)

